

Table of Contents
What Is RAGreduces AI hallucinations and How It Works
Definition: RAGreduces AI hallucinations by pairing a retriever (which fetches relevant documents) with a generator (which writes the answer). Instead of relying only on a model’s training data, RAG retrieves fresh, verifiable context and then generates a response grounded in that context. This is why RAGreduces AI hallucinations in tasks that demand factual accuracy.
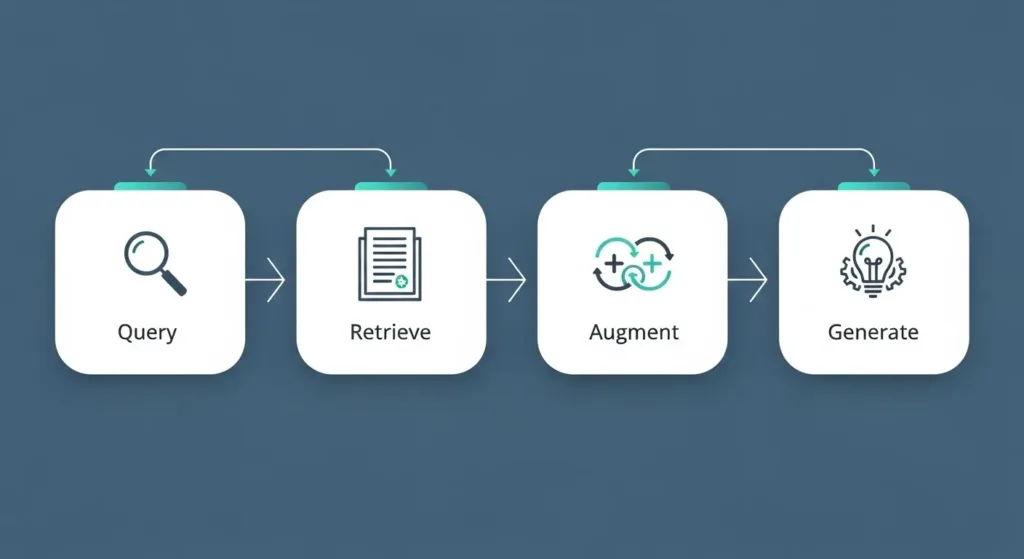
How it works (simple flow):
- User query → the system parses the question.
- Retrieve → a search component finds top-matching passages from a knowledge base.
- Augment → the passages are appended to the model’s prompt.
- Generate → the model crafts an answer using the retrieved facts.
- (Optional) Re-rank & cite → the system can score passages and surface sources for transparency.
Why RAGreduces AI hallucinations Is a Breakthrough in AI Accuracy
The main reason RAGreduces AI hallucinations so effectively lies in how it reshapes the model’s relationship with information. Traditional large language models (LLMs) generate answers based solely on what they’ve learned during training — a static memory frozen in time. This causes hallucinations when the model confidently “invents” details that sound right but are actually false.
RAG changes that dynamic completely. By introducing a retrieval layer, the model actively searches for the most relevant and recent information before responding. It no longer depends on memory alone — it grounds its answers in facts drawn from verified documents, articles, or databases. This “grounding” process is what ensures that RAGreduces AI hallucinations in domains where precision is crucial, like scientific writing, financial analytics, or medical summaries.
Moreover, studies from Microsoft Research and DeepMind confirm that RAG’s architecture not only boosts factual accuracy but also improves interpretability. Developers can trace how and why the model reached a certain conclusion, adding a layer of explainability that traditional LLMs lack.
For a broader perspective on factual integrity in AI systems, see our internal article [[Internal: Building Trust in Generative AI Outputs]].

Real-World Applications of RAGreduces AI hallucinations
RAGreduces AI hallucinations wherever answers must be grounded in verifiable sources, not guesswork. Here are practical use cases:
- Customer support & help centers: Pulls exact steps from manuals, tickets, and FAQs so responses reflect current policies, reducing escalations and repeat contacts.
- Enterprise search & knowledge ops: Unifies wikis, docs, and email threads; employees get source-linked answers instead of stale summaries.
- Compliance & legal summarization: Surfaces clauses from contracts and regulations; citations let teams verify every claim.
- Healthcare knowledge assistants: Retrieves peer-reviewed guidance and drug monographs; RAGreduces AI hallucinations by anchoring recommendations to trusted references (for education, not diagnosis).
- Financial research notes: Grounds definitions, metrics, and filing excerpts in the original documents (educational analysis, not investment advice).
- Education & research tools: Produces reading guides and literature overviews that point back to journals and textbooks.
- Productivity copilots: Drafts emails, PRDs, and briefs with inline sources from the company repository.
For a deeper dive into choosing the right approach, see our internal guide [[Internal: RAG vs Fine-Tuning — When to Use Each]].

How RAGreduces AI hallucinations Improves Trust and Transparency
When answers are traceable to sources, users trust them. By attaching citations and showing retrieved snippets, RAGreduces AI hallucinations and gives teams a clear audit trail. Product managers can verify where a claim came from, analysts can reproduce steps, and compliance can review evidence before sign-off. This source-first workflow is why RAGreduces AI hallucinations in high-stakes domains: every statement can be checked against the underlying documents rather than a model’s “memory.” For practical setup tips and citation patterns, You can also explore external best-practice frameworks such as the NIST AI Risk Management Framework and Stanford’s overview on grounded generation & RAG. In short, transparent retrieval + visible sources = fewer errors, more trust—exactly how RAGreduces AI hallucinations delivers.
Challenges and Future of RAGreduces AI hallucinations
RAG’s promise is huge, but production reality is delightfully stubborn. The hardest challenges fall into four buckets:
- Latency vs. depth of retrieval: Bigger indexes and smarter re-rankers improve grounding but slow responses. Engineering trade-offs (caching, vector compression, hybrid BM25+vector search) are essential to keep RAGreduces AI hallucinations without making users wait.
- Knowledge freshness & drift: Sources evolve. If the index isn’t refreshed (and old passages aren’t down-weighted), models can cite obsolete facts. Pipelines need scheduled re-ingestion, deduplication, and “freshness scoring.”
- Source quality & bias: Grounded doesn’t mean correct if your corpus is noisy. Curate aggressively, track document provenance, and prefer primary sources. That’s how RAGreduces AI hallucinations while avoiding “confidently wrong” answers.
- Evaluation at scale: Offline exact-match metrics miss nuance. Teams are adopting mixed evals: factuality checks, citation validity, and human spot-audits on critical queries to prove that RAGreduces AI hallucinations in real workloads.
What’s next: Expect growth in structured retrieval (tables, graphs), multi-hop reasoning over chains of documents, and guardrails that verify claims before output. Also rising: privacy-preserving RAG on encrypted or on-prem data, plus small local models paired with rich enterprise indexes.
For a practical, adjacent read that complements deployment choices, see our on-site article [[Internal: AI Tools for Entrepreneurs Guide]].
Conclusion: The Road Ahead for RAGreduces AI hallucinations
RAG’s trajectory is clear: better retrieval, smarter grounding, and tighter evaluation loops. Teams that bake sourcing into every answer will see measurable gains in trust and quality. As vector databases, re-ranking, and claim-checking mature, RAGreduces AI hallucinations more consistently across domains—from customer support to research. For technical depth, see the original RAG paper by Lewis et al. on arXiv and a practical architecture overview on the NVIDIA Technical Blog. The playbook is straightforward: curate high-quality corpora, monitor drift, and evaluate with citation validity—not just accuracy. Done well, RAGreduces AI hallucinations and turns generative AI into a dependable, auditable partner.
FAQs about RAGreduces AI hallucinations
Q1. Is RAG a replacement for fine-tuning?
Not necessarily. Fine-tuning adapts a model’s style or domain; RAGreduces AI hallucinations by grounding answers in retrieved sources. Many teams combine both.
Q2. Do I need a vector database?
It helps, but it’s not mandatory. Hybrid search (BM25 + vectors) often yields the best recall, which means RAGreduces AI hallucinations more reliably on diverse queries.
Q3. How do I evaluate results?
Track factuality, citation validity, and coverage on a fixed test set. Human spot checks on critical queries confirm that RAGreduces AI hallucinations beyond simple accuracy scores.
Q4. What about private data?
Use on-prem or VPC deployments and encrypt indexes. Access controls ensure retrieval only surfaces documents a given user is allowed to see.
Getting Started with RAGreduces AI hallucinations (Quick Setup)
Kick off a minimal pipeline to prove value fast—then scale.
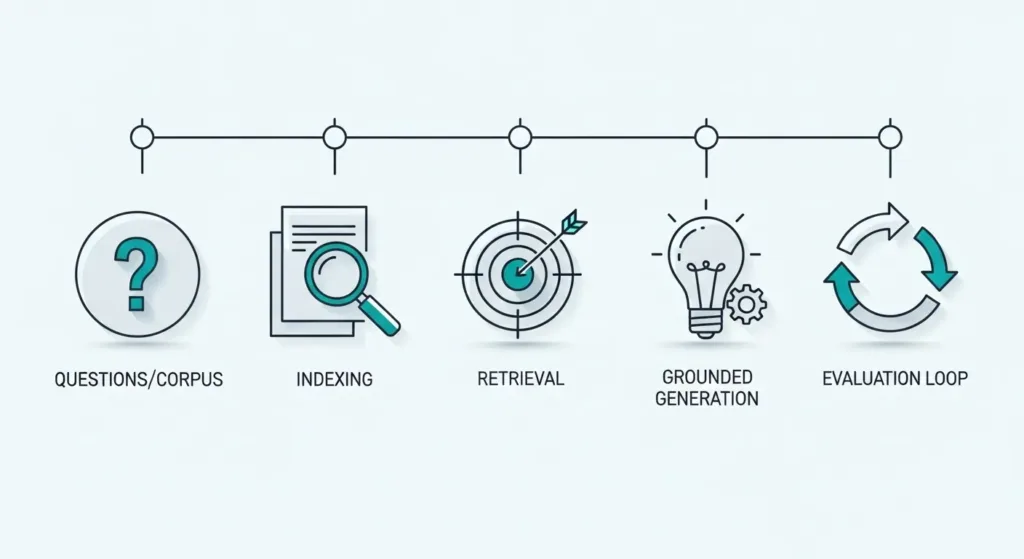
Step 1 — Define your questions & corpus:
List 20–50 frequent queries (support tickets, docs). Collect clean sources: PDFs, wikis, product manuals. High-quality inputs are how RAGreduces AI hallucinations from day one.
Step 2 — Ingest & index:
Parse to text, chunk (200–500 tokens), store metadata (title, URL, date). Build a hybrid index (BM25 + vectors) so recall stays strong on both keyword and semantic queries.
Step 3 — Retrieve:
For each user query, pull top-k passages (k≈5–10). Add a re-ranker to boost relevance; this often tightens grounding and ensures RAGreduces AI hallucinations in edge cases.
Step 4 — Generate with grounding:
Construct a prompt that includes the query, retrieved snippets, and strict instructions: “answer only from the snippets; if unsure, say so.” This guardrail helps RAGreduces AI hallucinations without heavy model surgery.
Step 5 — Evaluate & iterate:
Track factuality, citation validity, latency, and coverage on a fixed test set. Close the loop by adding missed documents and pruning noisy ones. For a practical walkthrough, see our internal guide [[Internal: RAG Quickstart Checklist]].

Best Practices & Guardrails for RAGreduces AI hallucinations
To make sure RAGreduces AI hallucinations consistently in production, bake these practices into your pipeline:
- Curate the corpus first: Remove duplicates, mark source authority, and track provenance (author, date, URL). Garbage in → hallucinations out.
- Right-size chunks: 200–500 tokens with sentence-aligned boundaries; include titles and section headers so RAGreduces AI hallucinations via richer context.
- Hybrid retrieval: Combine BM25 (keywords) with dense vectors (semantic). Re-rank top 50→10 using cross-encoder for precision.
- Strict prompting: Instruct the model to answer only from retrieved snippets and to say “I don’t know” when evidence is missing.
- Citation discipline: Attach source IDs next to each claim. Prefer primary documents; flag low-confidence spans for review.
- Evaluation loop: Track factuality, citation validity, coverage, latency, and user satisfaction. Regression test with a fixed query set.
- Freshness & drift control: Schedule re-ingestion; decay old documents; alert on conflicting sources.
- Safety rails: Redact PII, enforce access controls, and block generation when retrieval returns restricted content.
- Caching & observability: Cache hot queries, log retrieval hits/misses, and visualize end-to-end traces to see where RAGreduces AI hallucinations or where it slips.
Template prompt (snippet):
“Answer using only the provided snippets. Cite the snippet ID after each factual claim. If the snippets don’t contain the answer, say ‘No sufficient evidence found.’ Do not add outside knowledge.”

Measuring Impact—Metrics & Benchmarks for RAGreduces AI hallucinations
You can’t improve what you don’t measure. Use a small, stable evaluation set (50–200 queries) and track:
- Factuality (@k): Percentage of answers fully supported by retrieved snippets.
- Citation validity: Share of claims with correct, non-broken, on-topic sources.
- Grounding density: How many key sentences in the answer are backed by at least one snippet.
- Answer coverage: Portion of queries where the system provides a useful, evidence-based answer (rather than abstaining).
- Latency (P50/P95): Time from query to answer, including retrieval and re-ranking.
- User acceptance rate: Click-through, “was this helpful?” votes, or task completion.
Workflow: freeze a baseline, run weekly regression tests, and diff failures to see where evidence was missing or ranking slipped. A dashboard that ties each metric to example queries makes it obvious whether RAGreduces AI hallucinations in the ways that matter to your users. For setup tips and a sample scorecard, see our internal checklist [[Internal: RAG Evaluation Playbook]].
Final Takeaways & Next Steps for RAGreduces AI hallucinations
RAG turns guesswork into grounded answers. Curate a clean corpus, adopt hybrid retrieval with re-ranking, and enforce “answer-from-evidence” prompts—this is how RAGreduces AI hallucinations in real products. Keep a tight eval loop (factuality, citation validity, latency) and refresh your index to prevent drift. If you’re starting now, ship a minimal pilot in one workflow, measure impact, then expand to adjacent use cases. For a quick recap of setup essentials, revisit our internal checklist [[Internal: RAG Quickstart Checklist]] and the comparison guide [[Internal: RAG vs Fine-Tuning — When to Use Each]].
Next steps:
- Define 50 core queries and collect high-trust sources.
- Build a BM25+dense index and add a cross-encoder re-ranker.
- Enforce citation rules in prompts; log retrieval hits/misses.
- Run weekly regression tests and prune noisy documents.
